Recordsets
New in version 8.0: This page documents the New API added in Odoo 8.0 which should be the primary development API going forward. It also provides information about porting from or bridging with the "old API" of versions 7 and earlier, but does not explicitly document that API. See the old documentation for that.
Interaction with models and records is performed through recordsets, a sorted set of records of the same model.
Warning
contrary to what the name implies, it is currently possible for recordsets to contain duplicates. This may change in the future.
Methods defined on a model are executed on a recordset, and their self is
a recordset:
class AModel(models.Model):
_name = 'a.model'
def a_method(self):
# self can be anywhere between 0 records and all records in the
# database
self.do_operation()
Iterating on a recordset will yield new sets of a single record ("singletons"), much like iterating on a Python string yields strings of a single characters:
def do_operation(self):
print self # => a.model(1, 2, 3, 4, 5)
for record in self:
print record # => a.model(1), then a.model(2), then a.model(3), ...
Field access
Recordsets provide an "Active Record" interface: model fields can be read and written directly from the record, but only on singletons (single-record recordsets). Setting a field's value triggers an update to the database:
>>> record.name
Example Name
>>> record.company_id.name
Company Name
>>> record.name = "Bob"
Trying to read or write a field on multiple records will raise an error.
Accessing a relational field (Many2one,
One2many, Many2many)
always returns a recordset, empty if the field is not set.
Danger
each assignment to a field triggers a database update, when setting
multiple fields at the same time or setting fields on multiple records
(to the same value), use write():
# 3 * len(records) database updates
for record in records:
record.a = 1
record.b = 2
record.c = 3
# len(records) database updates
for record in records:
record.write({'a': 1, 'b': 2, 'c': 3})
# 1 database update
records.write({'a': 1, 'b': 2, 'c': 3})
Record cache and prefetching
Odoo maintains a cache for the fields of the records, so that not every field access issues a database request, which would be terrible for performance. The following example queries the database only for the first statement:
record.name # first access reads value from database
record.name # second access gets value from cache
To avoid reading one field on one record at a time, Odoo prefetches records and fields following some heuristics to get good performance. Once a field must be read on a given record, the ORM actually reads that field on a larger recordset, and stores the returned values in cache for later use. The prefetched recordset is usually the recordset from which the record comes by iteration. Moreover, all simple stored fields (boolean, integer, float, char, text, date, datetime, selection, many2one) are fetched altogether; they correspond to the columns of the model's table, and are fetched efficiently in the same query.
Consider the following example, where partners is a recordset of 1000
records. Without prefetching, the loop would make 2000 queries to the database.
With prefetching, only one query is made:
for partner in partners:
print partner.name # first pass prefetches 'name' and 'lang'
# (and other fields) on all 'partners'
print partner.lang
The prefetching also works on secondary records: when relational fields are read, their values (which are records) are subscribed for future prefetching. Accessing one of those secondary records prefetches all secondary records from the same model. This makes the following example generate only two queries, one for partners and one for countries:
countries = set()
for partner in partners:
country = partner.country_id # first pass prefetches all partners
countries.add(country.name) # first pass prefetches all countries
Set operations
Recordsets are immutable, but sets of the same model can be combined using various set operations, returning new recordsets. Set operations do not preserve order.
record in setreturns whetherrecord(which must be a 1-element recordset) is present inset.record not in setis the inverse operationset1 <= set2andset1 < set2return whetherset1is a subset ofset2(resp. strict)set1 >= set2andset1 > set2return whetherset1is a superset ofset2(resp. strict)set1 | set2returns the union of the two recordsets, a new recordset containing all records present in either sourceset1 & set2returns the intersection of two recordsets, a new recordset containing only records present in both sourcesset1 - set2returns a new recordset containing only records ofset1which are not inset2
Other recordset operations
Recordsets are iterable so the usual Python tools are available for
transformation (map(), sorted(),
ifilter(), ...) however these return either a
list or an iterator, removing the ability to
call methods on their result, or to use set operations.
Recordsets therefore provide these operations returning recordsets themselves (when possible):
filtered()returns a recordset containing only records satisfying the provided predicate function. The predicate can also be a string to filter by a field being true or false:
# only keep records whose company is the current user's records.filtered(lambda r: r.company_id == user.company_id) # only keep records whose partner is a company records.filtered("partner_id.is_company")
sorted()returns a recordset sorted by the provided key function. If no key is provided, use the model's default sort order:
# sort records by name records.sorted(key=lambda r: r.name)
mapped()applies the provided function to each record in the recordset, returns a recordset if the results are recordsets:
# returns a list of summing two fields for each record in the set records.mapped(lambda r: r.field1 + r.field2)
The provided function can be a string to get field values:
# returns a list of names records.mapped('name') # returns a recordset of partners record.mapped('partner_id') # returns the union of all partner banks, with duplicates removed record.mapped('partner_id.bank_ids')
Environment
The Environment stores various contextual data used by
the ORM: the database cursor (for database queries), the current user
(for access rights checking) and the current context (storing arbitrary
metadata). The environment also stores caches.
All recordsets have an environment, which is immutable, can be accessed
using env and gives access to the current user
(user), the cursor
(cr) or the context
(context):
>>> records.env
<Environment object ...>
>>> records.env.user
res.user(3)
>>> records.env.cr
<Cursor object ...)
When creating a recordset from an other recordset, the environment is inherited. The environment can be used to get an empty recordset in an other model, and query that model:
>>> self.env['res.partner']
res.partner
>>> self.env['res.partner'].search([['is_company', '=', True], ['customer', '=', True]])
res.partner(7, 18, 12, 14, 17, 19, 8, 31, 26, 16, 13, 20, 30, 22, 29, 15, 23, 28, 74)
Altering the environment
The environment can be customized from a recordset. This returns a new version of the recordset using the altered environment.
sudo()creates a new environment with the provided user set, uses the administrator if none is provided (to bypass access rights/rules in safe contexts), returns a copy of the recordset it is called on using the new environment:
# create partner object as administrator env['res.partner'].sudo().create({'name': "A Partner"}) # list partners visible by the "public" user public = env.ref('base.public_user') env['res.partner'].sudo(public).search([])
with_context()- can take a single positional parameter, which replaces the current environment's context
- can take any number of parameters by keyword, which are added to either the current environment's context or the context set during step 1
# look for partner, or create one with specified timezone if none is # found env['res.partner'].with_context(tz=a_tz).find_or_create(email_address)
with_env()- replaces the existing environment entirely
Common ORM methods
search()Takes a search domain, returns a recordset of matching records. Can return a subset of matching records (
offsetandlimitparameters) and be ordered (orderparameter):>>> # searches the current model >>> self.search([('is_company', '=', True), ('customer', '=', True)]) res.partner(7, 18, 12, 14, 17, 19, 8, 31, 26, 16, 13, 20, 30, 22, 29, 15, 23, 28, 74) >>> self.search([('is_company', '=', True)], limit=1).name 'Agrolait'
Tip
to just check if any record matches a domain, or count the number of records which do, use
search_count()create()Takes a number of field values, and returns a recordset containing the record created:
>>> self.create({'name': "New Name"}) res.partner(78)
write()Takes a number of field values, writes them to all the records in its recordset. Does not return anything:
self.write({'name': "Newer Name"})
browse()Takes a database id or a list of ids and returns a recordset, useful when record ids are obtained from outside Odoo (e.g. round-trip through external system) or when calling methods in the old API:
>>> self.browse([7, 18, 12]) res.partner(7, 18, 12)
exists()Returns a new recordset containing only the records which exist in the database. Can be used to check whether a record (e.g. obtained externally) still exists:
if not record.exists(): raise Exception("The record has been deleted")
or after calling a method which could have removed some records:
records.may_remove_some() # only keep records which were not deleted records = records.exists()
ref()Environment method returning the record matching a provided external id:
>>> env.ref('base.group_public') res.groups(2)
ensure_one()checks that the recordset is a singleton (only contains a single record), raises an error otherwise:
records.ensure_one() # is equivalent to but clearer than: assert len(records) == 1, "Expected singleton"
Creating Models
Model fields are defined as attributes on the model itself:
from openerp import models, fields
class AModel(models.Model):
_name = 'a.model.name'
field1 = fields.Char()
Warning
this means you can not define a field and a method with the same name, they will conflict
By default, the field's label (user-visible name) is a capitalized version of
the field name, this can be overridden with the string parameter:
field2 = fields.Integer(string="an other field")
For the various field types and parameters, see the fields reference.
Default values are defined as parameters on fields, either a value:
a_field = fields.Char(default="a value")
or a function called to compute the default value, which should return that value:
def compute_default_value(self):
return self.get_value()
a_field = fields.Char(default=compute_default_value)
Computed fields
Fields can be computed (instead of read straight from the database) using the
compute parameter. It must assign the computed value to the field. If
it uses the values of other fields, it should specify those fields using
depends():
from openerp import api
total = fields.Float(compute='_compute_total')
@api.depends('value', 'tax')
def _compute_total(self):
for record in self:
record.total = record.value + record.value * record.tax
dependencies can be dotted paths when using sub-fields:
@api.depends('line_ids.value') def _compute_total(self): for record in self: record.total = sum(line.value for line in record.line_ids)
- computed fields are not stored by default, they are computed and
returned when requested. Setting
store=Truewill store them in the database and automatically enable searching searching on a computed field can also be enabled by setting the
searchparameter. The value is a method name returning a Domains:upper_name = field.Char(compute='_compute_upper', search='_search_upper') def _search_upper(self, operator, value): if operator == 'like': operator = 'ilike' return [('name', operator, value)]
to allow setting values on a computed field, use the
inverseparameter. It is the name of a function reversing the computation and setting the relevant fields:document = fields.Char(compute='_get_document', inverse='_set_document') def _get_document(self): for record in self: with open(record.get_document_path) as f: record.document = f.read() def _set_document(self): for record in self: if not record.document: continue with open(record.get_document_path()) as f: f.write(record.document)
multiple fields can be computed at the same time by the same method, just use the same method on all fields and set all of them:
discount_value = fields.Float(compute='_apply_discount') total = fields.Float(compute='_apply_discount') @depends('value', 'discount') def _apply_discount(self): for record in self: # compute actual discount from discount percentage discount = record.value * record.discount record.discount_value = discount record.total = record.value - discount
onchange: updating UI on the fly
When a user changes a field's value in a form (but hasn't saved the form yet), it can be useful to automatically update other fields based on that value e.g. updating a final total when the tax is changed or a new invoice line is added.
- computed fields are automatically checked and recomputed, they do not need
an
onchange for non-computed fields, the
onchange()decorator is used to provide new field values:@api.onchange('field1', 'field2') # if these fields are changed, call method def check_change(self): if self.field1 < self.field2: self.field3 = True
the changes performed during the method are then sent to the client program and become visible to the user
- Both computed fields and new-API onchanges are automatically called by the client without having to add them in views
It is possible to suppress the trigger from a specific field by adding
on_change="0"in a view:<field name="name" on_change="0"/>
will not trigger any interface update when the field is edited by the user, even if there are function fields or explicit onchange depending on that field.
Note
onchange methods work on virtual records assignment on these records
is not written to the database, just used to know which value to send back
to the client
Low-level SQL
The cr attribute on environments is the
cursor for the current database transaction and allows executing SQL directly,
either for queries which are difficult to express using the ORM (e.g. complex
joins) or for performance reasons:
self.env.cr.execute("some_sql", param1, param2, param3)
Because models use the same cursor and the Environment
holds various caches, these caches must be invalidated when altering the
database in raw SQL, or further uses of models may become incoherent. It is
necessary to clear caches when using CREATE, UPDATE or DELETE in
SQL, but not SELECT (which simply reads the database).
Clearing caches can be performed using the
invalidate_all() method of the
Environment object.
Compatibility between new API and old API
Odoo is currently transitioning from an older (less regular) API, it can be necessary to manually bridge from one to the other manually:
- RPC layers (both XML-RPC and JSON-RPC) are expressed in terms of the old API, methods expressed purely in the new API are not available over RPC
- overridable methods may be called from older pieces of code still written in the old API style
The big differences between the old and new APIs are:
- values of the
Environment(cursor, user id and context) are passed explicitly to methods instead - record data (
ids) are passed explicitly to methods, and possibly not passed at all - methods tend to work on lists of ids instead of recordsets
By default, methods are assumed to use the new API style and are not callable from the old API style.
Tip
calls from the new API to the old API are bridged
when using the new API style, calls to methods defined using the old API are automatically converted on-the-fly, there should be no need to do anything special:
>>> # method in the old API style
>>> def old_method(self, cr, uid, ids, context=None):
... print ids
>>> # method in the new API style
>>> def new_method(self):
... # system automatically infers how to call the old-style
... # method from the new-style method
... self.old_method()
>>> env[model].browse([1, 2, 3, 4]).new_method()
[1, 2, 3, 4]
Two decorators can expose a new-style method to the old API:
model()the method is exposed as not using ids, its recordset will generally be empty. Its "old API" signature is
cr, uid, *arguments, context:@api.model def some_method(self, a_value): pass # can be called as old_style_model.some_method(cr, uid, a_value, context=context)
multi()the method is exposed as taking a list of ids (possibly empty), its "old API" signature is
cr, uid, ids, *arguments, context:@api.multi def some_method(self, a_value): pass # can be called as old_style_model.some_method(cr, uid, [id1, id2], a_value, context=context)
Because new-style APIs tend to return recordsets and old-style APIs tend to return lists of ids, there is also a decorator managing this:
returns()the function is assumed to return a recordset, the first parameter should be the name of the recordset's model or
self(for the current model).No effect if the method is called in new API style, but transforms the recordset into a list of ids when called from the old API style:
>>> @api.multi ... @api.returns('self') ... def some_method(self): ... return self >>> new_style_model = env['a.model'].browse(1, 2, 3) >>> new_style_model.some_method() a.model(1, 2, 3) >>> old_style_model = pool['a.model'] >>> old_style_model.some_method(cr, uid, [1, 2, 3], context=context) [1, 2, 3]
Model Reference
Method decorators
Fields
Basic fields
Relational fields
Inheritance and extension
Odoo provides three different mechanisms to extend models in a modular way:
- creating a new model from an existing one, adding new information to the copy but leaving the original module as-is
- extending models defined in other modules in-place, replacing the previous version
- delegating some of the model's fields to records it contains
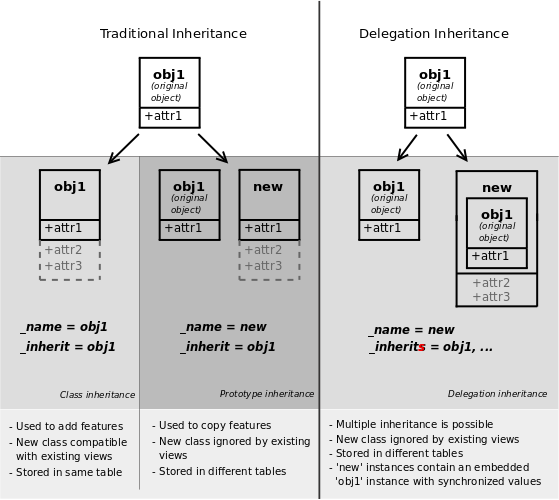
Classical inheritance
When using the _inherit and
_name attributes together, Odoo creates a new
model using the existing one (provided via
_inherit) as a base. The new model gets all the
fields, methods and meta-information (defaults & al) from its base.
and using them:
will yield:
the second model has inherited from the first model's check method and its
name field, but overridden the call method, as when using standard
Python inheritance.
Extension
When using _inherit but leaving out
_name, the new model replaces the existing one,
essentially extending it in-place. This is useful to add new fields or methods
to existing models (created in other modules), or to customize or reconfigure
them (e.g. to change their default sort order):
will yield:
Note
it will also yield the various automatic fields unless they've been disabled
Delegation
The third inheritance mechanism provides more flexibility (it can be altered
at runtime) but less power: using the _inherits
a model delegates the lookup of any field not found on the current model
to "children" models. The delegation is performed via
Reference fields automatically set up on the parent
model:
will result in:
and it's possible to write directly on the delegated field:
Warning
when using delegation inheritance, methods are not inherited, only fields
Domains
A domain is a list of criteria, each criterion being a triple (either a
list or a tuple) of (field_name, operator, value) where:
field_name(str)- a field name of the current model, or a relationship traversal through
a
Many2oneusing dot-notation e.g.'street'or'partner_id.country' operator(str)an operator used to compare the
field_namewith thevalue. Valid operators are:=- equals to
!=- not equals to
>- greater than
>=- greater than or equal to
<- less than
<=- less than or equal to
=?- unset or equals to (returns true if
valueis eitherNoneorFalse, otherwise behaves like=) =like- matches
field_nameagainst thevaluepattern. An underscore_in the pattern stands for (matches) any single character; a percent sign%matches any string of zero or more characters. like- matches
field_nameagainst the%value%pattern. Similar to=likebut wrapsvaluewith '%' before matching not like- doesn't match against the
%value%pattern ilike- case insensitive
like not ilike- case insensitive
not like =ilike- case insensitive
=like in- is equal to any of the items from
value,valueshould be a list of items not in- is unequal to all of the items from
value child_ofis a child (descendant) of a
valuerecord.Takes the semantics of the model into account (i.e following the relationship field named by
_parent_name).
value- variable type, must be comparable (through
operator) to the named field
Domain criteria can be combined using logical operators in prefix form:
'&'- logical AND, default operation to combine criteria following one another. Arity 2 (uses the next 2 criteria or combinations).
'|'- logical OR, arity 2.
'!'logical NOT, arity 1.
Tip
Mostly to negate combinations of criteria
Individual criterion generally have a negative form (e.g.
=->!=,<->>=) which is simpler than negating the positive.
Example
To search for partners named ABC, from belgium or germany, whose language is not english:
[('name','=','ABC'),
('language.code','!=','en_US'),
'|',('country_id.code','=','be'),
('country_id.code','=','de')]
This domain is interpreted as:
(name is 'ABC')
AND (language is NOT english)
AND (country is Belgium OR Germany)
Porting from the old API to the new API
- bare lists of ids are to be avoided in the new API, use recordsets instead
- methods still written in the old API should be automatically bridged by the ORM, no need to switch to the old API, just call them as if they were a new API method. See Automatic bridging of old API methods for more details.
search()returns a recordset, no point in e.g. browsing its resultfields.relatedandfields.functionare replaced by using a normal field type with either arelated=or acompute=parameterdepends()oncompute=methods must be complete, it must list all the fields and sub-fields which the compute method uses. It is better to have too many dependencies (will recompute the field in cases where that is not needed) than not enough (will forget to recompute the field and then values will be incorrect)- remove all
onchangemethods on computed fields. Computed fields are automatically re-computed when one of their dependencies is changed, and that is used to auto-generateonchangeby the client - the decorators
model()andmulti()are for bridging when calling from the old API context, for internal or pure new-api (e.g. compute) they are useless - remove
_default, replace bydefault=parameter on corresponding fields if a field's
string=is the titlecased version of the field name:name = fields.Char(string="Name")
it is useless and should be removed
- the
multi=parameter does not do anything on new API fields use the samecompute=methods on all relevant fields for the same result - provide
compute=,inverse=andsearch=methods by name (as a string), this makes them overridable (removes the need for an intermediate "trampoline" function) - double check that all fields and methods have different names, there is no warning in case of collision (because Python handles it before Odoo sees anything)
- the normal new-api import is
from openerp import fields, models. If compatibility decorators are necessary, usefrom openerp import api, fields, models - avoid the
one()decorator, it probably does not do what you expect - remove explicit definition of
create_uid,create_date,write_uidandwrite_datefields: they are now created as regular "legitimate" fields, and can be read and written like any other field out-of-the-box when straight conversion is impossible (semantics can not be bridged) or the "old API" version is not desirable and could be improved for the new API, it is possible to use completely different "old API" and "new API" implementations for the same method name using
v7()andv8(). The method should first be defined using the old-API style and decorated withv7(), it should then be re-defined using the exact same name but the new-API style and decorated withv8(). Calls from an old-API context will be dispatched to the first implementation and calls from a new-API context will be dispatched to the second implementation. One implementation can call (and frequently does) call the other by switching context.Danger
using these decorators makes methods extremely difficult to override and harder to understand and document
uses of
_columnsor_all_columnsshould be replaced by_fields, which provides access to instances of new-styleopenerp.fields.Fieldinstances (rather than old-styleopenerp.osv.fields._column).Non-stored computed fields created using the new API style are not available in
_columnsand can only be inspected through_fields- reassigning
selfin a method is probably unnecessary and may break translation introspection Environmentobjects rely on some threadlocal state, which has to be set up before using them. It is necessary to do so using theopenerp.api.Environment.manage()context manager when trying to use the new API in contexts where it hasn't been set up yet, such as new threads or a Python interactive environment:>>> from openerp import api, modules >>> r = modules.registry.RegistryManager.get('test') >>> cr = r.cursor() >>> env = api.Environment(cr, 1, {}) Traceback (most recent call last): ... AttributeError: environments >>> with api.Environment.manage(): ... env = api.Environment(cr, 1, {}) ... print env['res.partner'].browse(1) ... res.partner(1,)
Automatic bridging of old API methods
When models are initialized, all methods are automatically scanned and bridged if they look like models declared in the old API style. This bridging makes them transparently callable from new-API-style methods.
Methods are matched as "old-API style" if their second positional parameter
(after self) is called either cr or cursor. The system also
recognizes the third positional parameter being called uid or user and
the fourth being called id or ids. It also recognizes the presence of
any parameter called context.
When calling such methods from a new API context, the system will
automatically fill matched parameters from the current
Environment (for cr,
user and
context) or the current recordset (for id
and ids).
In the rare cases where it is necessary, the bridging can be customized by decorating the old-style method:
- disabling it entirely, by decorating a method with
noguess()there will be no bridging and methods will be called the exact same way from the new and old API styles defining the bridge explicitly, this is mostly for methods which are matched incorrectly (because parameters are named in unexpected ways):
cr()- will automatically prepend the current cursor to explicitly provided parameters, positionally
cr_uid()- will automatically prepend the current cursor and user's id to explictly provided parameters
cr_uid_ids()- will automatically prepend the current cursor, user's id and recordset's ids to explicitly provided parameters
cr_uid_id()will loop over the current recordset and call the method once for each record, prepending the current cursor, user's id and record's id to explicitly provided parameters.
Danger
the result of this wrapper is always a list when calling from a new-API context
All of these methods have a
_context-suffixed version (e.g.cr_uid_context()) which also passes the current context by keyword.- dual implementations using
v7()andv8()will be ignored as they provide their own "bridging"